Основное управление индексацией сайта в поисковых систем осуществляется с помощью текстового файла robots.txt, расположенного в корне сайта.
Описание директив robots.txt на Яндексе и Google.
Закрыть от индексации весь сайт:
User-agent: *
Disallow: /Закрыть весь сайт, кроме главной страницы:
User-agent: *
Disallow: /
Allow: /$Запретить индексирование одной страницы:
User-agent: *
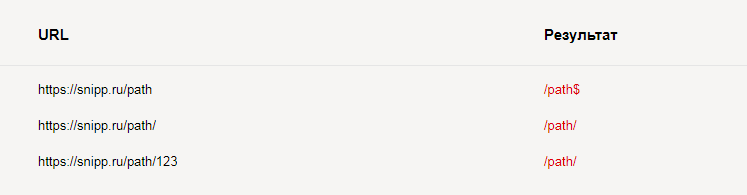
Disallow: /page.htmlЗапретить индексировать каталог и всё его содержимое:
User-agent: *
Disallow: /path$
Disallow: /path/Результат проверки:
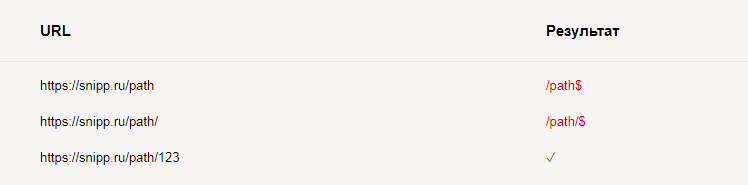
Запрет индексировать каталог, но оставить его содержимое:
User-agent: *
Disallow: /path$
Disallow: /path/$Результат проверки:
Закрыть всё, корме одной категории:
User-agent: *
Disallow: /
Allow: /path/$Результат проверки:

Запретить индексировать картинки можно по расширению файлов:
User-agent: *
Disallow: /*.jpg$
Disallow: /*.jpeg$
Disallow: /*.gif$
Disallow: /*.png$
Disallow: /*.webp$Запретить только для Яндекса можно по имени бота:
User-agent: YandexImages
Disallow: /Запретить индексацию изображений только для Google:
User-agent: Googlebot-Image
Disallow: /По расширению файла:
User-agent: *
Disallow: /*.doc$
Disallow: /*.docx$
Disallow: /*.xls$
Disallow: /*.xlsx$
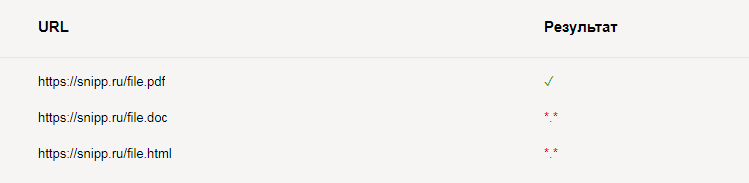
Disallow: /*.pdf$Запретить все расширения, кроме pdf:
User-agent: *
Disallow: *.*$
Allow: *.pdf$Результат проверки:
Если в адресах сайта используется приписка .htm, .html и .xml, то их необходимо тоже разрешить.
Яндекс поддерживает директиву Clean-param и рекомендуется использовать её, в Google такой поддержки нет, поэтому GET-параметры всё равно придется закрывать дрективани Disallow/Allow.
Запретить все GET-параметры:
User-agent: *
Disallow: /*?*Запретить определенный GET-параметр:
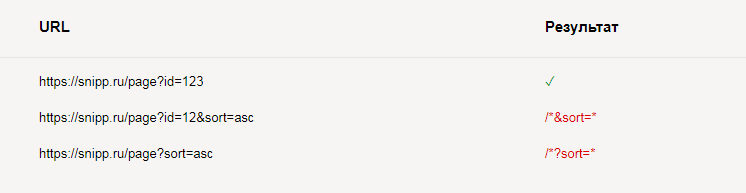
User-agent: *
Disallow: /*?sort=
Disallow: /*&sort=Результат проверки:
Запретить все GET-параметры, кроме:
User-agent: *
Disallow: /*?*
Allow: /*?id=
Allow: /*&id=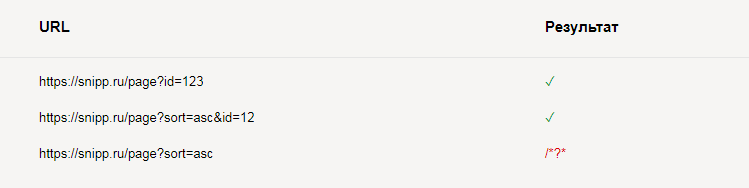
Запретить обход поисковыми роботами определенных страниц можно метатегом robots, достаточно поместить его в <head> страницы:
<!doctype html>
<html lang="en">
<head>
<meta name="robots" content="noindex">
</head>
<body>
...
</body>
</html>Метатег robots только для Яндекса:
<meta name="yandex" content="noindex, nofollow" />Метатег robots только для Google:
<meta name="googlebot" content="noindex">Оба поисковика поддерживают управление индексированием с помощью заголовка «X-Robots-Tag». Например в PHP:
Пример в PHP:
header("X-Robots-Tag: noindex");В .htaccess:
Header Set X-Robots-Tag "noindex"rel="nofollow", например: <a href="https://example.com" rel="nofollow">Ссылка</a>rel="nofollow" |
Робот будет игнорировать ссылку. |
rel="ugc" |
Для ссылок, опубликованных пользователями, например в комментарии или записи на форуме. |
rel="sponsored" |
Если ссылка носит рекламный характер, указывает на рекламное место или размещение в рамках партнерской программы с другим сайтом. |
Можно указать несколько значений через запятую или пробел:
<a href="https://example.com" rel="ugc nofollow">Ссылка</a>
<a href="https://example.com" rel="ugc,nofollow">Ссылка</a>У атрибута «rel» есть другие значения:
rel="noreferrer" |
В Google Analytics трафик, приходящий по ссылкам, будет отображаться как прямой трафик вместо указания источника. |
|
|
Препятствует тому, чтобы страница назначения могла получить доступ к исходной странице. |
Закрыть часть контента можно только для Яндекса, элементом <noindex>:
<noindex>текст, индексирование которого нужно запретить</noindex><!--noindex-->текст, индексирование которого нужно запретить<!--/noindex-->